网友评论()2015.03.10 总第69期 作者:xukkx
导语:要说2015年至2016年间风靡整个围棋界和人工智能领域的一件大事,莫过于新科围棋计算机程序AlphaGo挑战著名世界冠军韩籍棋手李世石九段了。从赛前的舆论风向上看,除了部分计算机界专家对AlphaGo的获胜充满信心之外,普遍的看法还是偏向于人类顶尖棋手能够战胜围棋计算机程序。如李开复博士曾在知乎表示人工智能若要战胜李世石,还需要1至2年时间的磨练。然而第一天的战果却令大部分人大跌眼镜,经过一场三个半小时的大战,AlphaGo执白中盘战胜李世石,令世人震惊。那么,人工智能经过几十年的发展,究竟到了何种地步?真的可以取代人类智能,达到一个令人类遥不可及的境界了吗?本文通过对人工智能历史的发展的梳理,对此问题做一个简单的探讨。

人机围棋大战现场
一、 人工智能的起源与发展
人工智能,即人类使用计算机对人类智能的模仿,让机器“学会”人类在某一领域的专业技能。早在公元前384-322年,Aristotle在其著作《工具论》中提出形式逻辑。Bacon在《新工具》中提出了归纳法。莱布尼茨(Leibnitz)提出了通用符号和推理计算的概念,这些都是人工智能研究的萌芽。进入19世纪以来,数理逻辑等学科的进展,为人工智能的诞生奠定了基石。布尔(Boole)创立的布尔代数与哥德尔(Godel)提出的不完备理论,以及图灵(Turing)提出的自动机理论,为电子计算机的发明提供了理论基础。1943年,McClloch和Pitts提出了MP神经网络模型,开创了人工智能中的重要领域——神经网络的研究,1945年随着ENIAC电子数字计算机的诞生,人工智能得到了不断的发展和应用。如今,人工智能已经渗入了普通人生活的方方面面。比如在人们网购的过程中,网站可以通过用户浏览网页的习惯来“猜测”其可能感兴趣的商品,并推荐给该用户,这项技术就使用到了人工智能中重要领域“机器学习”中的重要方法。而机器学习中的重要算法——神经网络,则与本文的主角AlphaGo围棋程序息息相关。
二、 为什么围棋程序是人工智能重大挑战?
早在人工智能发展初期的20世纪50年代,来自IBM工程研究组的Samuel就开发出了跳棋程序,具有初步的学习能力,可以在与人对弈的过程中不断地积累经验,提高自己的棋艺。并且在1959年,这个程序战胜了其设计者本人,1962年,再次击败一位州跳棋冠军。由此可见,通过机器学习人类的棋类游戏并与人类对弈,一直是人工智能应用中的一个很令人感兴趣的话题。早期人工智能学者对于”计算机很快就会战胜人类“这个话题曾经过分地乐观过,60年代初,人工智能创始人Simon等甚至乐观地预言:十年内数字计算机将取代人类获得国际象棋世界冠军。
然而经过深入的研究,人们却发现人工智能所遇到的困难比想象中的多得多,比如,Samuel的跳棋程序在击败州冠军后无法再前进一步。而在国际象棋对弈中,人类棋手可以在每步三分钟的时间限制中,通过直觉与理解,在若干个定式中选择对自己最为有利的下法。对于优秀棋手而言,通常可以通过思考预测到5步之后的情形,而对于电脑程序而言,每行走一步却面临着平均每颗棋子超过30余种选择,合计起来为了预测5步以后的情形,需要考虑下法居然多达1015 种可能,计算机每走一步,则平均每秒需要检查百万种可能的走法,以当时电脑的计算能力而言,走一步棋需要花费三十年时间。可见如果电脑不能通过对棋局的判断来减少行棋的复杂度,仅凭蛮力,程序很难击败人类顶尖棋手。1968年,在得知人工智能研究者John McCarthy和Donald Michie”十年内电脑将击败国际象棋世界冠军”的预言后,著名国际象棋世界大师David Levy与人工智能学者打下一个非常著名的赌注:没有电脑国际象棋程序可以在十年内击败我。赌金为1250英镑。在这十年中,David Levy成功了击败了所有电脑挑战者,并在1978年9月在一场六局对决中,以4.5比1.5的比分战胜当时的终极电脑程序Chess 4.7,从而最终赢得了自己打下的这个赌。
尽管赢下了赌注,电脑却在第四局对局中获得了胜利,这是计算机程序历史上第一次击败人类国际象棋大师。为此,David Levy写道:尽管我在十年前的断言是正确的,然而我的机器对手在这十年中,比我打赌时进步的太多了,从此以后,再也没有会令我震惊的事情发生了(指电脑程序最终击败人类特级大师)。那么,这十年中电脑程序在什么方面取得了进展呢?
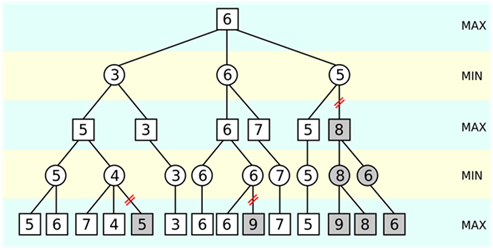
剪枝法示意
转机来源于一种被称为“剪枝法”的算法被用于象棋程序的估值函数之中。估值函数,即电脑对于当前棋局优劣进行判断的根据,估值函数根据当前的局面算得一个分数,来判断此棋局是否对自己就有利,最后,选择最高得分的那一步作为自己最终的行棋。如果可选择的步数太多,未经过特别的优化,则会陷入上文提到的穷举困境之中。顾名思义,“剪枝法”就如同剪掉一棵大树不重要的“旁枝”一般,去除掉完全不可能的走法,因故可以减少复杂度,对估值函数最后的选择起到了优化的作用,这么一整套算法被称为“ alpha-beta 剪枝结合搜索树算法”。
随着数十年来算法的不断改进,到了七十年代末,国际象棋程序已经可以击败人类的顶级高手了。1976年,在Paul Masson美国国际象棋锦标赛B级的比赛中, Chess4.7的前身,美国西北大学开发的Chess4.5击败了人类选手,这是计算机程序首次击败人类棋手夺取的人类锦标。到了1982年,计算机象棋程序每秒可估算1500种不同的走法,并击败绝大部分人类棋手。可见,程序所取得的进步并非靠计算硬件水平的提高,而是通过算法上的优化,提高程序鉴别“胜负手”的能力和速度,在一个可行的范围内找出人类棋手的弱点,从而击溃之。最著名的“人机”大战是1997年俄罗斯国际特级大师卡斯帕罗夫与IBM公司研发的超级计算机深蓝(Deep Blue)的对决,深蓝最终的胜出表明人类最强国际象棋特级大师已经彻底被人工智能所击败,从此再也难以从计算机程序手中拿走一胜了。
那么既然人工智能算法在国际象棋上已取得了大捷,基于同样原理的算法能否在更加复杂的围棋中击败人类的顶级棋手呢?答案是否定的,在简单的规则下,标准的19×19棋盘内,共有361个点,大概有10170种下法,而宇宙中已知原子的数量只有1080个,可见围棋棋局之复杂远超国际象棋,这也难怪创建高水平的围棋程序被称为人工智能领域的重大挑战。比较而言,在国际象棋程序中行之有效的“搜索树”(search tree)算法,在围棋程序中的推广却不甚理想,难以和职业围棋选手抗衡。在AlphaGo出现之前,基于传统算法的围棋程序仅能达到业余棋手的水平,远远不能令人满意。而AlphaGo横空出世后,首战即5比0大胜欧洲围棋冠军樊麾二段,展现出不俗的实力。因此,说AlphaGo的出现严重动摇了人类智能在围棋上的垄断,是毫无问题的。那么,AlphaGo及其研发的团队Google DeepMind都有什么亮点呢?
三、 AlphaGo体现了当今人工智能的最高水平
在谈及AlphaGo及其开发团队Google DeepMind之前,必须先简介一下其领导者哈萨比斯(Demis Hassabis),可以说,在他出现之前,几乎所有研究者都认为在十年内人工智能战胜围棋大师的机会是渺茫的。而在他出现以后,几乎所有人都在惊呼人工智能已破解了围棋这一历史难题,甚至在极短的时间内两次让研究成果上了《Nature》杂志的封面。因此,卫报(TheGuardian)直呼Hassabis就是人工智能领域的超级英雄。我认为Hassabis个人完全配得上这个称谓。

Hassabis
据《卫报》的报道,Hassabis的终生目标就是开发出“通用”的人工智能程序,来解决生活中的一切问题。他分别取得了剑桥大学和伦敦大学学院的计算机科学和神经科学学位。Hassabis称自己领导的项目就是“21世纪的阿波罗项目”,这也难怪AlphaGo在击败了李世石九段之后Hassabis第一时间在twitter对团队的祝贺中用“登月”形容围棋程序击败人类顶尖棋手的意义。而在此之前,DeepMind通过对近期人工智能技术中最热门的一项技术——深度学习网络,加上”强化学习”的方法使计算机通过自学的方式在上世纪七八十年代的雅达利经典游戏中,获得了近乎人类的表现。而这一成果在更早先的时候登上了《Nature》杂志的封面。拥有千年历史的古老游戏与三十年前的像素游戏纷纷被人工智能攻破,恐怕在未来若干年间,人工智能在任何游戏中都强于人类也不会是太令人震惊的事情吧。
以上所有人工智能领域的发展,都离不开一项技术在近年来的突破,那就是深度学习(Deep Learning),深度学习是传统的神经网络技术的再发展。何为神经网络?神经网络就是人类提出的一套模拟大脑工作方式的计算机算法。人的大脑有100亿个神经元,人类对于环境的感知,对于未知事物的认知与神经元的“可塑性”息息相关,人脑通过对特定的人物或者感兴趣的知识进行“建模”,神经元形成相互连接的“神经网络”,并通过互联神经元的连接强度,即突触权值来储存知识。而所谓人工神经网络,就是将化简后人脑的神经元模型实现于电子计算机之上,从而得到类似于人脑的功能,使计算机可以通过“学习”从外界环境中获取知识。最初等的人工神经网络出现在20世纪50年代末的“感知机”模型,初步展现了人工神经网络的学习能力,后来的研究表明感知机模型只能解决很有限的几类问题。神经网络的最新发展——深度学习方法源于Geoffrey Hinton教授等人三十多年来的不懈努力研究和推广,自诞生之日起,即在机器学习领域中大放异彩,通过深度学习方法训练出来的模型,在某些特别的图像识别和语音识别的任务中,甚至有超过人类的表现。在当下,深度学习方法是最接近人类大脑的人工智能学习算法。那么将深度学习网络应用于围棋程序AlphaGo又与传统的国际象棋程序深蓝有什么区别呢?
据AlphaGo官方博客介绍,AlphaGo采用了一种更加“通用”的人工智能方法,即采用将改进的蒙特卡洛决策树算法与深度神经网络算法相结合的方法构建最终的学习系统。其中,深度神经网络由一个多达12层的包含上百万个神经元节点的神经网络构成,其包括两个部分:策略网络与价值网络。具体的技术细节在此不赘言,仅说说其发挥的作用。策略网络在当前给定的棋局中,负责预测下一步的走棋,并对下一步走棋的好坏进行打分,如果是好棋,就打高分,最终,最高分的走法被策略网络选为下一步棋的走法。而这个最高分如要如何评定呢?此时,现存于人类数据库中的围棋棋谱的作用就体现出来了,对比以往高手对决的棋谱,如果如此走法能得到最终的胜利,那就是好棋,这步就可以评高分,因为以往棋谱的胜负是已知的,反之亦然。在这里,人类历史上的大量围棋起了训练数据的作用,好比老师在“监督”学生做练习,答对了就给高分,答错了不给分。通过对于三千万步人类棋谱的学习,AlphaGo对于人类棋手下一步走棋的预测准确率高达57%(之前为43%)。策略网络的作用好比“模仿”人类棋手的各种走法,以达到预测的效果。
然而仅凭模仿无法击败最顶级的人类高手。因此,AlphaGo增加了价值网络来判断当前的局面,到底对哪一方有利,这一步类似于国际象棋程序中的估值函数,而具体的实现方法却有所不同,象棋程序中需要人工调整估值函数中的权重,以达到最好的效果,甚至需要水平极高的国际特级大师参与调整参数。而围棋程序的局势评估相当困难,只能通过深度学习网络之间自我训练的方法来达到良好的效果。与国际象棋程序相比,围棋好比人类用自己的知识训练电脑,使其达到人类高手的水平,而国际象棋程序则是人类亲自将行棋的方法与逻辑设计为电脑程序,最终由计算机代表人类与人类高手进行对弈。根据Facebook人工智能组研究员田渊栋博士介绍,为了得到合适的价值网络模型,AlphaGo通过自我对局三千万盘的方式训练得到了强有力的价值网络模型,最后再通过传统的蒙特卡洛搜索树方法结合以上两种深度神经网络模型,最终得到了完整的AlphaGo围棋程序。可以说AlphaGo的研发是当今人工智能领域各类技术的集大成者,体现了人工智能技术的最高水平。
四、 人工智能超越人类还要多久?
李世石在围棋人机大战第一盘中的失利,几乎掀起了轩然大波,似乎一夜之间人工智能已经战胜人类智能,甚至人工智能完全超越人类智能的那一天似乎也不会遥远了。为此,需要对“人工智能”的概念做一个简单的澄清。
对于人工智能的看法,一直分两派不同的观点,一派是强人工智能,即通过不断地发展机器终将获得类人的自我意识,最终通过不断地自我进化获得远强于人类的智能水平。而另一派则认为人工智能只是对人类劳动的接管,仅在部分领域超越人类,全面超越人类智能只是一个梦想而已。
从目前的研究现状看,强人工智能的研究几乎陷入了停滞,远超过人类智能的强人工智能是否存在依然是个很有争议的话题,更不要说具体的研究方向了。而主流的机器学习技术,依然集中于对人类技能的学习,并通过学习的成果来解决实际的问题。比如说围棋程序AlphaGo,尽管比起国际象棋机器深蓝进步很大,然而本质上依然是在给定规则具体游戏上的探究,一旦改变了规则,甚至换不同规格的棋盘,AlphaGo就必须推倒重来,重新搜集相应棋谱来获得棋力了。很明显,这和人类所认识的“举一反三”类型的“创造知识”的智慧是不相符的。如果要问当今的人工智能是否达到了三岁小孩的智力水平,那也是一件无法比较的事情,因为通过不断地训练机器可以在特定技能上完胜小孩子,但是在一些看似简单的学习上,小孩子需要花费的精力却远小于机器。比如拿起桌子上的杯子喝水,对于小孩来说很容易学会,对于智能机器来说,却是件连问题是什么都很难描述清楚的事情,更不要说自主学习了。因此,在未来很长一段时间内,所谓人工智能,依然只是对人类技能的补充,好比工具,是对人类智慧的拓宽,即“机器使用人类的知识战胜了人类”,而远非到了远超人类智慧的地步。
当然,人类对于智能的理解还很浅。就拿上文所提的深度学习举例,虽然在实用中获得了广泛的应用,然而人们对其背后的数学机制依然不太清楚,不知道机器做出结论的依据是什么,甚至连Hassabis本人也说不清楚AlphaGo的棋力到底几何。或许直到人类对“智能是什么”这种问题的本质了解透彻之时,对于“人工智能能否超越人类”这个话题才能得到令人满意的答案吧。

兰台
凤凰历史特约记录员

凤凰历史 官方微信
微信扫描二维码
每天看精彩历史

所有评论仅代表网友意见,凤凰网保持中立