聚信立:做最好的爬虫,从底层说起
2017年09月05日 16:23:36
来源:楚北网

原标题:聚信立:做最好的爬虫,从底层说起

做基于大数据的风控,首先得有大数据,要有大数据,就需要从互联网上采集,而互联网数据采集的程序,大家都称之为“爬虫”。其实,互联网上的爬虫应该说无处不在,大到人尽皆知的谷歌百度,小到各式各样的刷票工具,毫不夸张地说,爬虫之于大数据,就像是一群搬大象的蚂蚁,昼夜忙忙碌碌,推动的是整个互联网世界的数据流动。
聚信立是最早一批把爬虫应用到风控领域的企业,作为业内的标杆,聚信立对爬虫技术的打磨几乎是到了精益求精的地步。
大家可能都知道,爬虫开发的技术门槛实际并不很高,开发一个简单网站的爬虫,每天自动爬100次,对一个有经验的程序猿来说只要一天,但是问题来了,如果网站需要登录呢?如果有100个网站呢?每天要爬100万次呢?网站每几天会改版呢?如何提供7*24小时的稳定服务?这样的问题层出不穷。
因此,一个完整的爬虫服务通常需要以下几个子系统:爬虫系统、数据解析系统、查询分析系统,可能还有分布式存储系统。面对各种互联网应用,爬虫实现的方式可能各异,但是一个优秀的爬虫系统应具备以下几种特征:
高性能:尽可能在最短的时间内抓取目标页面,并完成解析入库;
易维护:能够快速的增加目标数据源,并且可以及时的应对反爬措施;
易扩展:能够根据业务需求、资源使用情况,很容易的对爬虫服务规模自由扩展。
而风控领域一个生产级别的爬虫服务,日常管理几千个并行工作的爬虫节点是最基础的要求,那么,本文抛砖引玉,先跟大家聊聊爬虫节点集群的技术选型。
老生常谈:KVM vs Docker
做爬虫节点的集群,首先的选择一定是KVM虚拟机,最成熟的解决方案。用一张图简单介绍一下虚拟机的原理:
§ 基础设施(Infrastructure)。它可以是你的个人电脑,数据中心的服务器,或者是云主机。
§ 宿主操作系统(Host Operating System)。你的个人电脑之上,运行的可能是MacOS,Windows或者某个Linux发行版。
§ 虚拟机管理系统(Hypervisor)。利用Hypervisor,可以在主操作系统之上运行多个不同的从操作系统。类型1的Hypervisor有支持MacOS的HyperKit,支持Windows的Hyper-V以及支持Linux的KVM。类型2的Hypervisor有VirtualBox和VMWare。
§ 虚拟操作系统(Guest Operating System)。假设你需要运行3个相互隔离的爬虫节点,则需要使用Hypervisor启动3个虚拟操作系统,也就是3个虚拟机。

显然,每个虚拟机自带独立的GUEST OS,在保证了虚拟机应用的隔离性的同时,也带来了大量的资源开销,无论硬盘、CPU还是内存,这种需求驱动下,Docker容器带着下一代虚拟机技术的光环出现了。
轻量级是Docker相对KVM最大的特点,其实现原理可也用一张图说明:
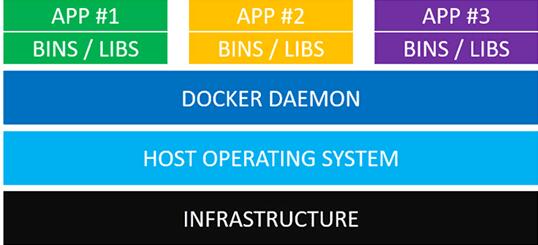
如图,与KVM最大的区别是Docker Daemon(守护进程),取代了Hypervisor,它是运行在操作系统之上的后台进程,利用Linux的LXC技术,管理Docker容器。Docker守护进程可以直接与宿主操作系统进行通信,为各个Docker容器分配资源;它还可以将容器与宿主操作系统隔离,并将各个容器互相隔离。
由于每个Docker容器不需要包含一套独立的Guest OS,与其他容器共享了大部分系统资源,因此性能方面优势巨大,单机部署上千个节点成为可能,而所有节点,可以通过一个标准的镜像文件来管理配置,一次配置,在任何地方都可以正常运行。这些特性,对于爬虫节点集群来说,是非常有吸引力的。
但是我们也知道,Docker在2013年横空出世以后,虽然倍受追捧,但始终没有达到完全替代KVM的程度,毕竟,Docker的设计初衷也不是一个KVM的替代品。从我们在爬虫集群的实践层面看,Docker集群由于在隔离性方面的先天缺陷,对网络资源和存储IO方面有许多瓶颈,比如说同一台物理机各个爬虫节点之间,如何有效分配CPU和带宽,从而保证互不争用?容器与宿主共用内核,存在安全隐患,如何防范容器对宿主的逃逸?凡此种种,使得我们在大规模使用Docker作为爬虫集群底层框架上持谨慎态度。
Hyper:真正的下一代虚拟机?
KVM和Docker之后,Hyper是我们近期最关注的虚拟机项目,原因就是它着手从根本上解决Docker的隔离性问题,同时又保持了可与Docker媲美的性能。还是一张图说明:

简单的说,同样在hypervisor的基础上,hyper的做法是采用guest kernel取代了guest OS,其实就是对OS的一个极致优化,省掉不必要的硬件扫描、设备初始化和引导过程等,使每个hyper容器只需要搭载一个足以承载应用的内核,而非一个完全模拟物理机的操作系统,从而大大降低了VM的开销。同时,由于每个容器都有各自独立的内核,并且和宿主操作系统的内核也分离开来,所有Hyper也继承了KVM那种硬件强制级别的隔离性。
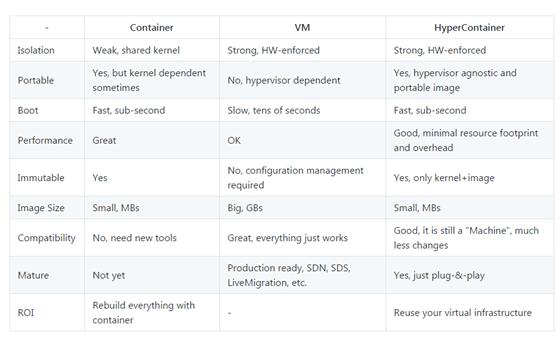
再一次,将Hyper与docker&kvm做下比较,应该说Hyper是一个技术层面有很大突破的项目(中国人做的,点赞),在思路上很好地结合了Docker与KVM各自的优势。
回到爬虫,Hyper有如下优点:
1. 节点之间内核独立,资源隔离性更强,使得系统安全风险降低
2. 可直接部署在物理机上,少了一层虚拟机,降低了运维的复杂度
3. API跟docker类似,方便二次开发集成
4. 启动跟docker一样的快速,可实现集群化应用快速更新
应该说,基于以上特点给了我们使用Hyper作为爬虫集群底层非常充分的理由。因此,今年以来,针对Hyper在爬虫上的应用,我们做了大量的尝试,也已经积累得了不少第一手的数据和实际的效果。当然,Hyper本身还处在发展阶段,无论技术支持、社区和商用化案例都还很缺乏,后续能否得到爆发性的发展,还是值得关注。
以上我们在爬虫底层节点集群技术选型上的一点经验分享,后续我们可以再继续慢慢说来,爬虫虽小,要做到最好,也是门大学问。


推荐












频道推荐

凤凰资讯官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128